

Was ist KI?
Generative KI ist ein Teil der Künstlichen Intelligenz. Der Begriff KI umfasst beispielsweise auch Algorithmen, die Gesichter erkennen oder Wetterprognosen erstellen. KI wird seid einigen Jahren vor allem dazu eingesetzt, Muster in große Datenmengen zu erkennen, zB. in welcher Kombination bestimmte Faktoren zusammen mit einem spezifischen Wetterereignis aufgetreten sind, sodass sich Ableitungen für die Zukunft aufstellen lassen. Andere KI-Algorithmen haben im Training errechnet, welche Attribute in Abbildungen zwei verschiedene Arten von Objekten unterscheiden lassen. So kann ein Smartphone beispielsweise bestimmte Merkmale in Gesichtern mit dem Gesicht des Nutzenden vergleichen und das Gerät entsprechend entsperren.
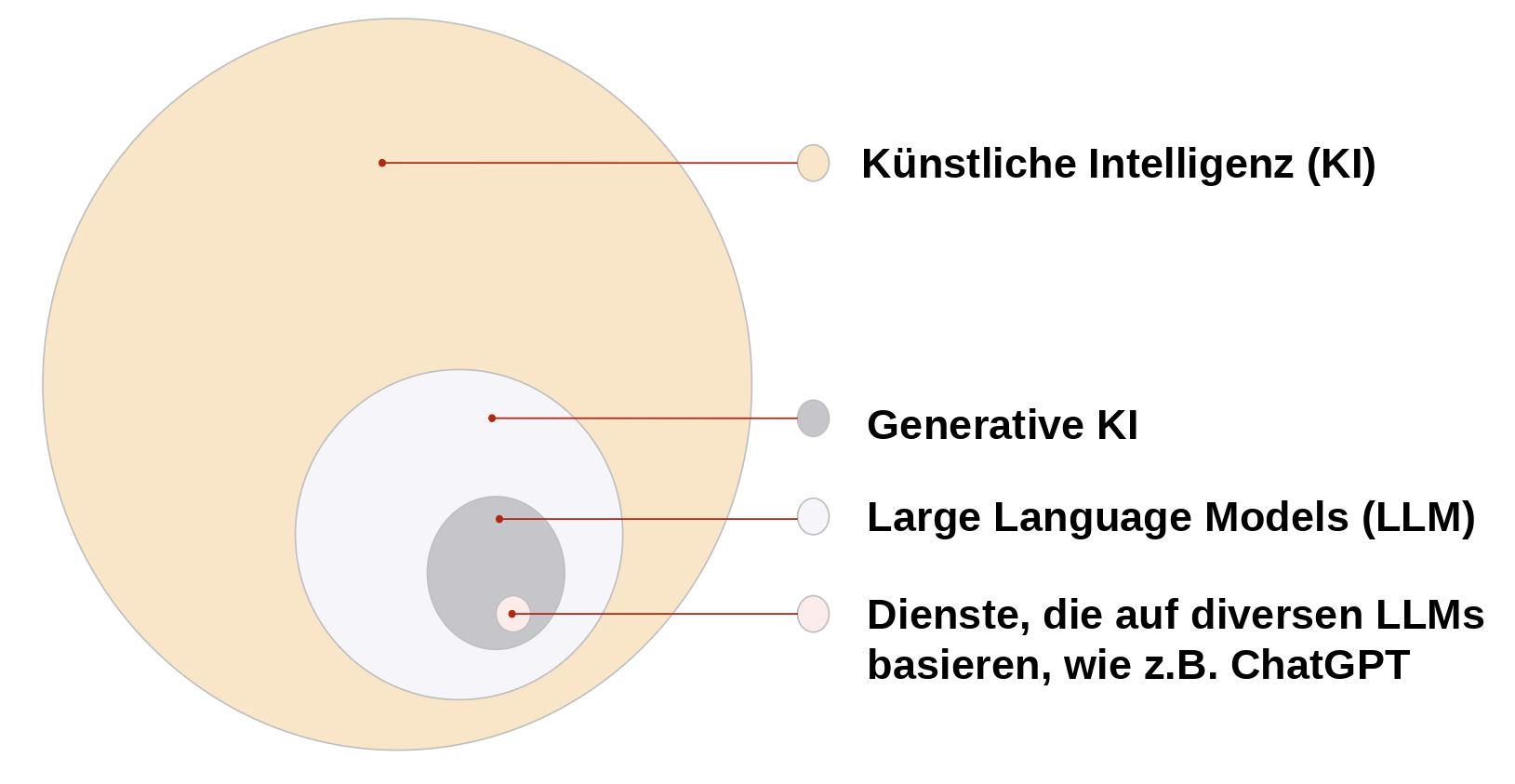
Es gibt also nicht „die KI“, sondern viele teils sehr unterschiedliche Algorithmen, die für verschiedene Aufgaben programmiert wurden. Gemeinsam ist ihnen, das sie mit einem Datensatz trainiert wurden, aus dem der Algorithmus Muster erkennt und Regeln ableitet. Danach ist es dem Algorithmus möglich, neue Daten zu klassifizieren ohne den Input eine*r Programmierer*in.
Wir fokussieren uns hier auf die generative KI und im Speziellen auf Large Language Models (vergleiche Abbildung oben), weil sie neue Implikationen für die Lehre und das Lernen in allen Fächern mit sich bringt und für alle prinzipiell frei zugänglich und nutzbar ist. Large Language Models (LLMs) werden von Diensten wie kiwi, ChatGPT oder Gemini genutzt, um Sprache zu generieren. Es gibt auch generative KI Algorithmen, die Bilder oder Videomaterial erstellen können, sowie multimodale Modelle, die diese Eigenschaften miteinander kombinieren.
Wie werden LLMs trainiert?
Damit ein LLM einen Output generieren kann, der der menschlichen Sprachnutzung sehr ähnlich ist und Informationen über die Welt enthält, ist eine möglichst große Datenmenge an natürlicher Sprache notwendig. Entsprechend werden LLMs mit verschiedensten im Internet zugänglichen Sprachdaten trainiert; also potentiell mit geschriebenen Texten auf Webseiten, Tonspuren aus Videos, Audioaufnahmen aus Podcasts und Hörbüchern. Denkbar wäre auch das Training mit sensiblen Daten wie beispielsweise aus Chatverläufen oder anderen Anwendungen. Diese Daten werden gesammelt zum Training der Algorithmen verwendet ohne das eine Klassifizierung von Sprachgebrauch oder inhaltlicher Richtigkeit erfolgt. Die Annahme dahinter ist, das eine genügend große Datenmenge diese kompensiert.
Das Ziel des Trainings solcher Algorithmen ist es, Muster in diesen Datensätzen zu erkennen, also zu erkennen, wie nah bestimmte Strukturen im Textzusammenhang zueinander stehen und somit sehr wahrscheinlich nacheinander oder im gleichen Kontext auftauchen. Diese Strukturen sind nicht unbedingt mit syntaktischen Begriffen (wie zB. einzelnen Wörtern oder Silben) zu klassifizieren, können aber Zeichenabfolgen oder Begriffe in nah zusammenstehenden Sätzen sein. Anhand dieser errechneten Wahrscheinlichkeiten generiert ein LLM dann Wörter, Sätze und Absätze. (näheres dazu im Video)
Dabei ist die inhaltliche Bedeutung, die wir diesen Sätzen zusprechen, nur ein Produkt aus der gelernten Wahrscheinlichkeitsabfolge. Es steht keine Intention oder ein inhaltliches Verständis hinter dem Output eines LLMs. Wir als Nutzende interpretieren erst die generierten Wörter und Sätze. Anders ist dies bei einer Konversation mit einem Menschen, unabhängig ob diese schriftlich oder verbal, direkt oder zeitversetzt erfolgt. Hier gibt es einen Sender der Sprache, der mit einem bestimmten Ziel eine Aussage trifft und intendiert, dass die verwendeten Worte eine ganz bestimmte Assoziation beim Empfänger auslösen, die er selbst teilt.
Wie funktionieren LLMs?
In 4 Minuten erklärt Ihnen dieses Video, wie LLMs funktionieren.
Weitere Infos zum Thema



Wollen Sie sich tiefer in den KI-Dschungel vorwagen?
Vielleicht haben Sie diese Mikromodule (MiMos) schon Ihren Studierenden empfohlen. Aber natürlich können Sie sich auch selbst damit fortbilden. Die MiMos sind kurze, fachlich fundierte Selbstlerneinheiten, die jederzeit ausschnitthaft oder vollständig in 90 Minuten bearbeitet werden können.

Willkommen im KI-Dschungel
Erfolgreiche KI-Nutzung erfordert Informationskompetenz und kritische Bewertung der Ergebnisse. Dieses MiMo erlaubt den Lernenden, KI-Tools effektiv und sensibilisiert für Fehlinterpretationen im wissenschaftlichen Kontext einzusetzen.

Wie textgenerative KI tickt – Expedition KI
Dieses Vertiefungsmodul leitet an, textgenerative KIs selbst auszuprobieren. Wozu eignen sie sich und wie sollten sie im Hochschulkontext eingesetzt werden?

Bild- und videogenerative KI – Expedition KI
Wie funktionieren bild- und videogenerative KI-Tools und wofür sind sie im Studium konkret nützlich? Die Reihe Expedition KI enthält Erfahrungsberichte und Tipps, mit denen generative KI selbst ausprobiert werden können.
Sie lesen lieber?

Über die UB Osnabrück haben Sie Zugriff auf das E-Book „Wissenschaftliches Schreiben mit KI“ von Isabella Buck, Competence & Career Center der Hochschule RheinMain.
Es erklärt einfach verständlich und anschaulich im Detail die Begriffe und Funktionsweise (Generativer) Künstlicher Intelligenz insbesondere der Large Language Models.